
「雜湊表(hash table)」,又可稱為「哈希表」,是透過鍵(key)值找到資料在記憶體位置的儲存方式。將數據透過雜湊函式(hash function)映射(map)到其在表中的對應位置後,可同步降低操作時的「空間複雜度」與「時間複雜度」。
雜湊函式(hash function)
可將我們熟悉的「明文(plaintext)」轉為長度與格式固定的「密文(ciphertext / cyphertext)。只要明文改變,密文就要跟著改變,且無法從密文反推明文。這個密文即為「雜湊值(hash value)」。
雜湊函式被廣泛應用於密碼學中,如區塊鏈即利用「加密雜湊函式(cryptographic hash function)」將資料加密。
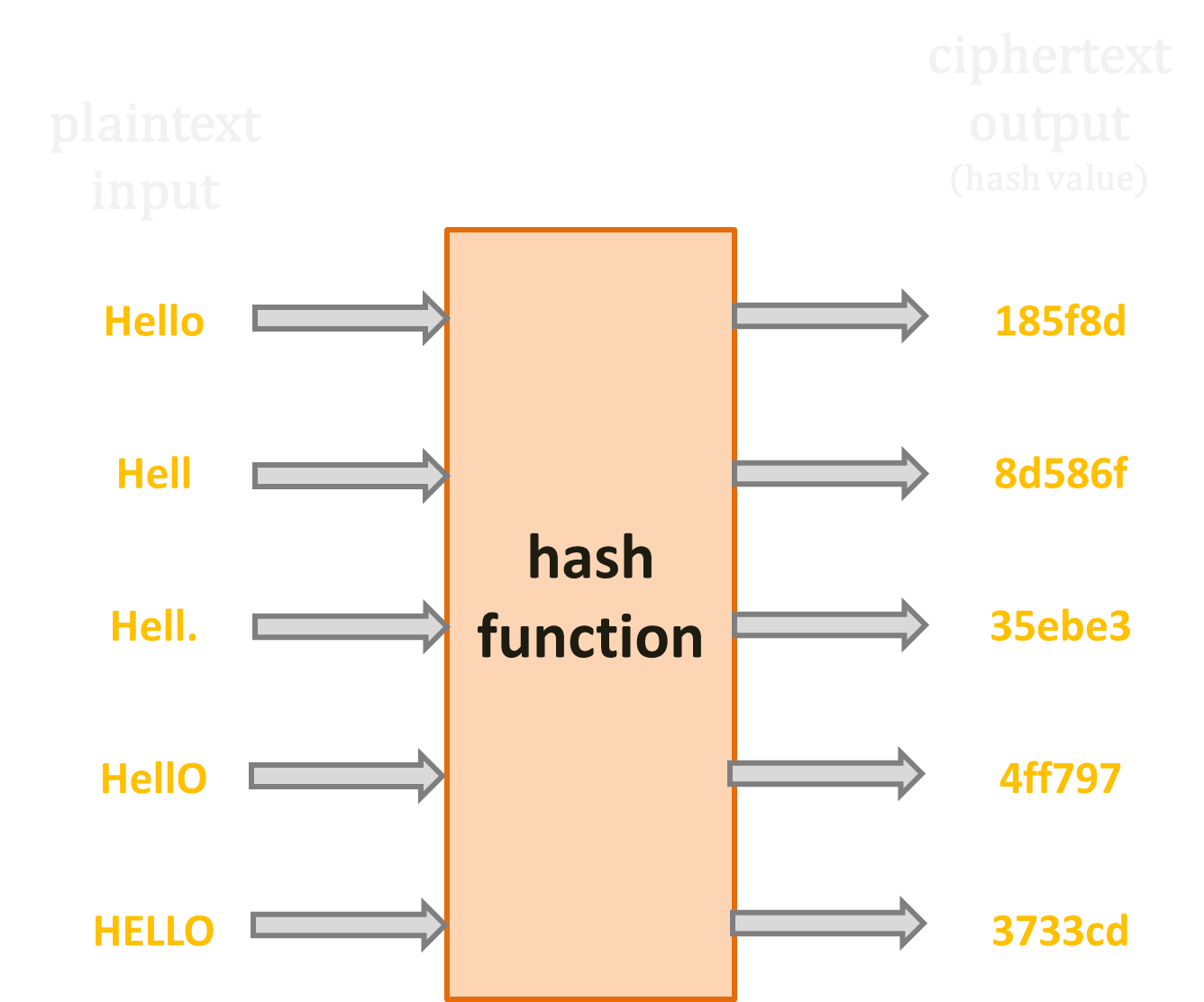
雜湊函式示意圖(取 SHA-256 前六碼為例)
雜湊函式運算方法
常見的雜湊函式以「除法」或「乘法」實現,兩者都可以透過資料的「key」值找到對應的記憶體存放位置。下列範例中,雜湊表為陣列,每筆資料的儲存位置都有對應的索引值。
「載荷因子(load factor)」代表資料個數(設為 n)與雜湊表大小(設為 m)的比例,其值越大,越容易產生多筆資料放在同一個空間的「雜湊衝突(hash collision)」現象。如果載荷因子大於 1,根據「鴿巢原理(pigeonhole principal)」,雜湊衝突將不可避免。

除法(division method)
取雜湊表大小為 m,每筆資料在雜湊表中的索引值(index)為「key % m」,其中 0≤index<m。
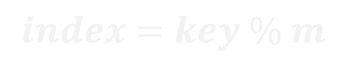
現假設有 A(key=11424)、B(key=6254)、C(key=4171)、D(key=554) 四筆資料,雜湊表共有 6 個儲存空間,載荷因子為 4/6=66.7%。四筆資料經雜湊函式以除法運算後,可得各自對應的位置如下:
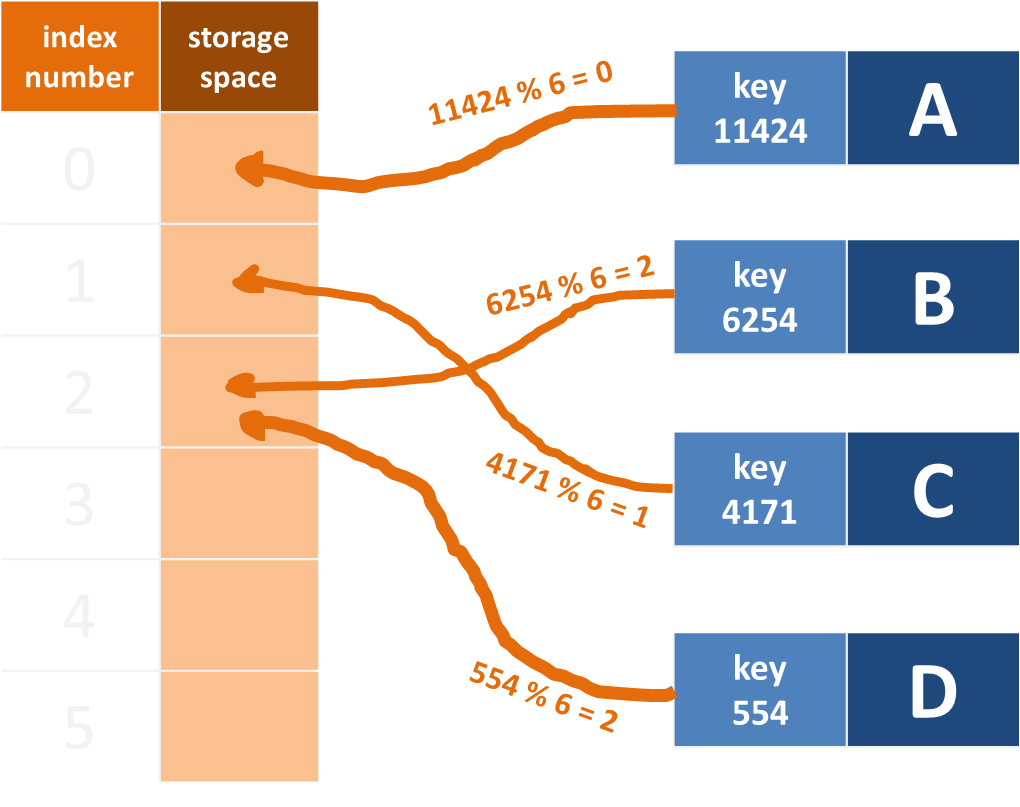
在上圖中,B、D 經過雜湊函式的模除運算後皆為 2,即會產生雜湊衝突。
使用除法進行雜湊函式運算時,「m」的值應遠離 2ᵖ,否則不管「key」值多大,當中十位數以上的數字都能夠被「m」整除,經模除運算的結果非常有限,將會產生非常多衝突。
乘法(multiplication method)
取雜湊表大小為 m,每筆資料在雜湊表中的索引值(index)為「[m·(( key · A)% 1)]」,其中 0≤index≤(m–1)。
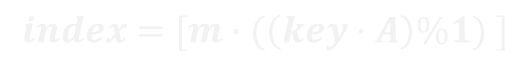
這樣的算法看似複雜,我們可以拆為下列幾個步驟一一理解:
- 將「key」值乘上一個小於 1 的無理數 A(常用 (√5–1)/2),得一個更大的無理數。
- 將步驟 1. 求得的大無理數模除 1,去掉整數部分,剩下小數。
- 將 m 乘以步驟 2. 求出的小數,將小數點右移,得介於 0~(m–1) 之間的無理數。
- 將步驟 3. 求出的無理數取高斯符號,得介於 0~(m–1) 之間的整數,這個整數就是「key」值的索引值。

各步驟與原理圖示如下,為了方便觀察,當中的「key」與「A」都轉為二進制(binary),因此第 2 步驟(黃色部分)的模除項目由 1 改為 2ʷ:
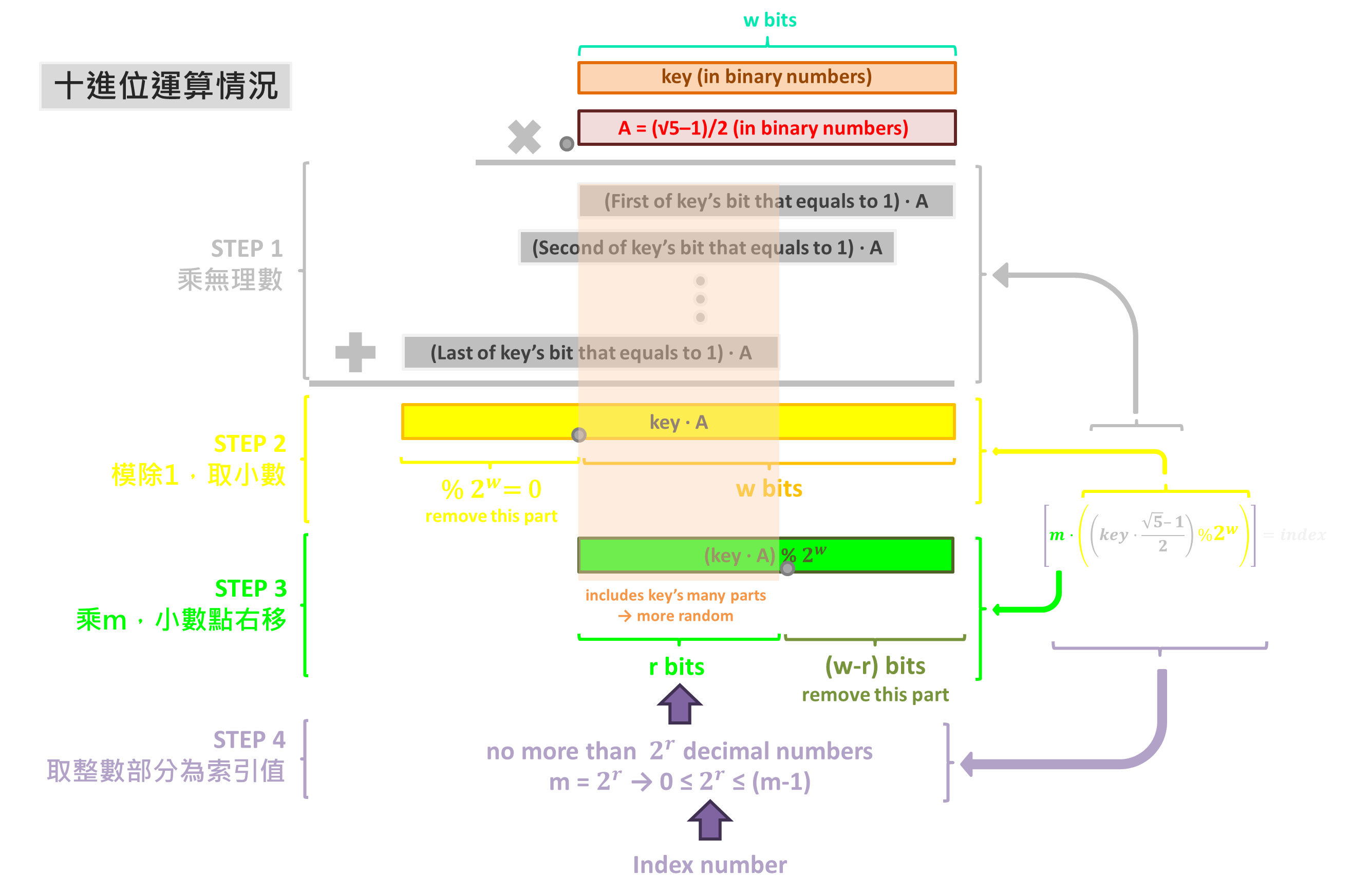
跟除法相比,乘法在進行上述步驟運算時,同步將「key」中更多不同的部分都納入考量,可以提高隨機性(參考上圖中央半透明橘框部分),且 m 不再有要遠離 2ᵖ 這個限制。
現假設一樣有 A(key=11424)、B(key=6254)、C(key=4171)、D(key=554) 四筆資料,雜湊表共有 6 個儲存空間,載荷因子為 4/6=66.7%。四筆資料經雜湊函式以乘法運算後,可得各自對應的位置如下:
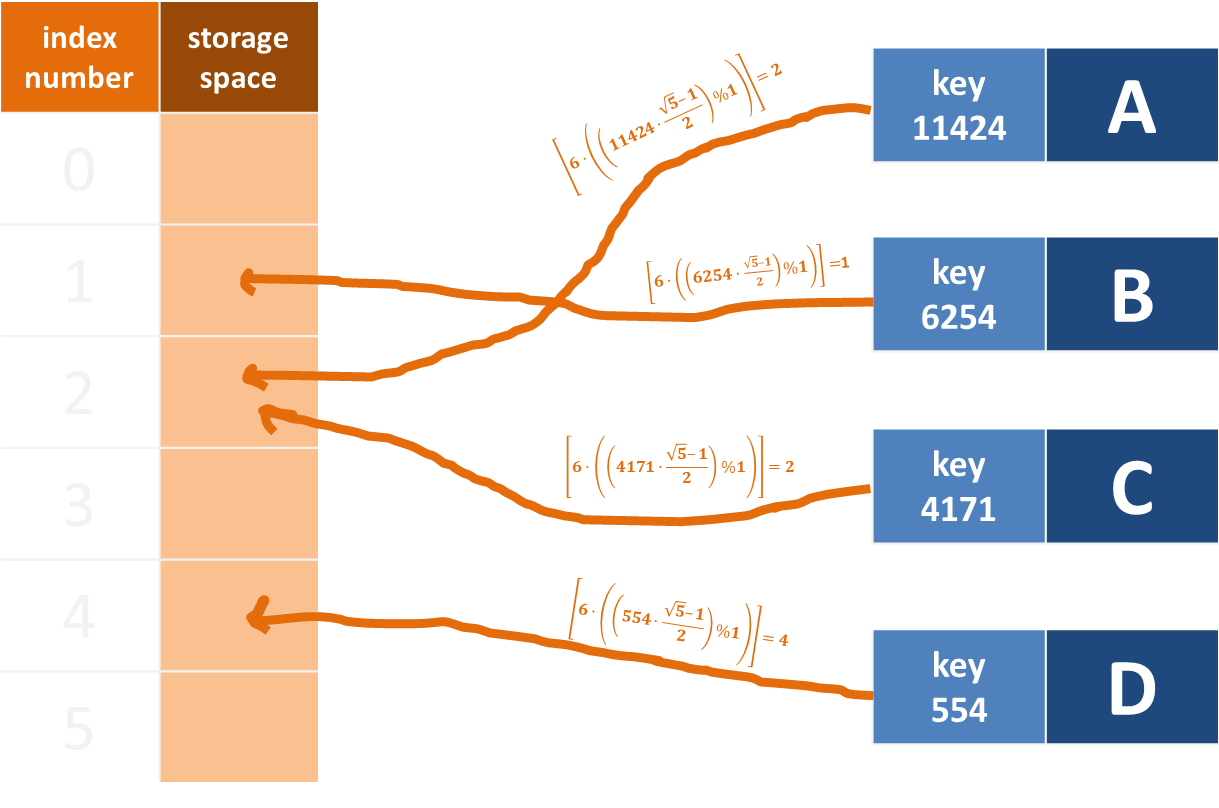
即便經過複雜的乘法運算,雜湊衝突依然不可避免。
處理雜湊衝突
常見的雜湊衝突處理方式可分為「封閉尋址法(closed addressing / chaining)」及「開放定址法(open addressing)」兩大類。
封閉尋址法(closed addressing / chaining)
在每個儲存空間中再生成新的子鏈狀儲存空間,可用「鏈結串列(linked list)」或「陣列(array)」實現。
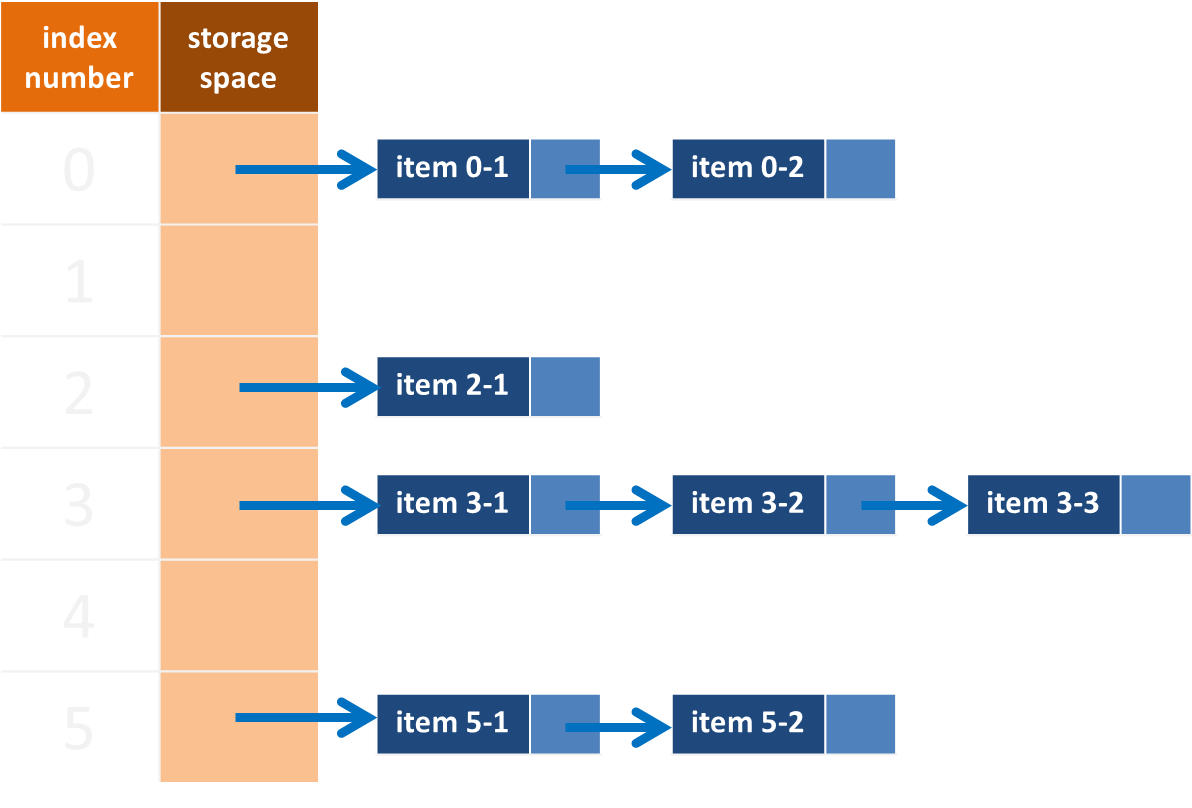
使用「鏈結串列(linked list)」實現封閉尋址
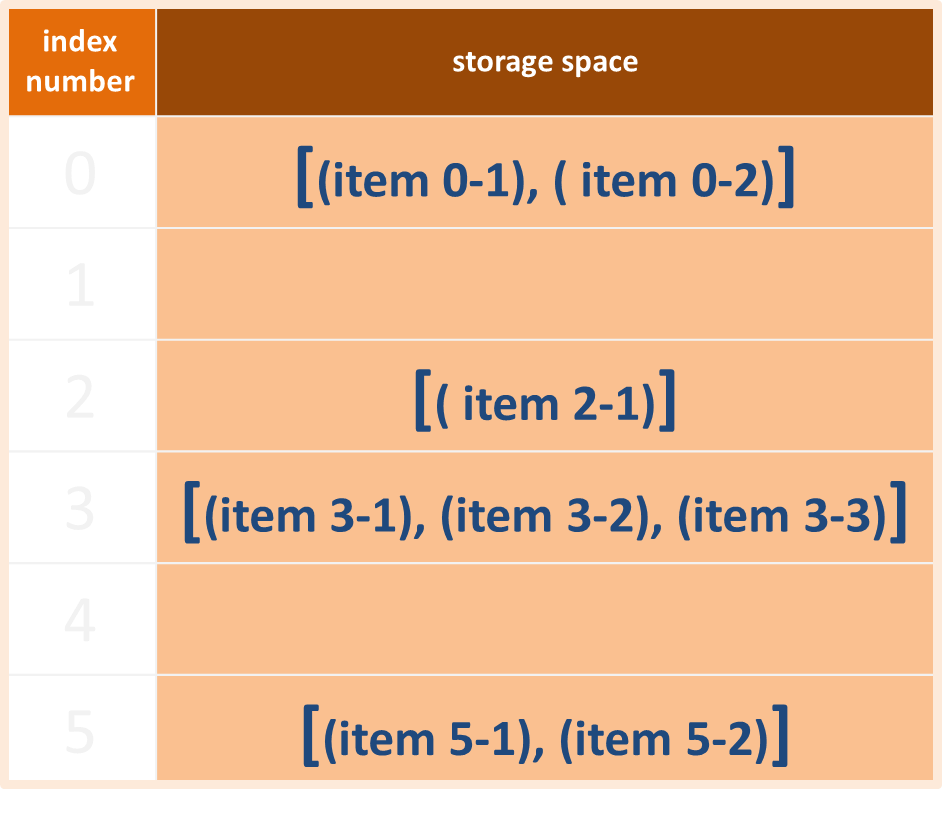
使用「陣列(array)」實現封閉尋址
開放定址法(open addressing)
透過「探測(probing)」尋找仍未儲存資料的儲存空間,主要可分為「線性探測法(linear probing)」與「平方探測法(quadratic probing)」兩種。
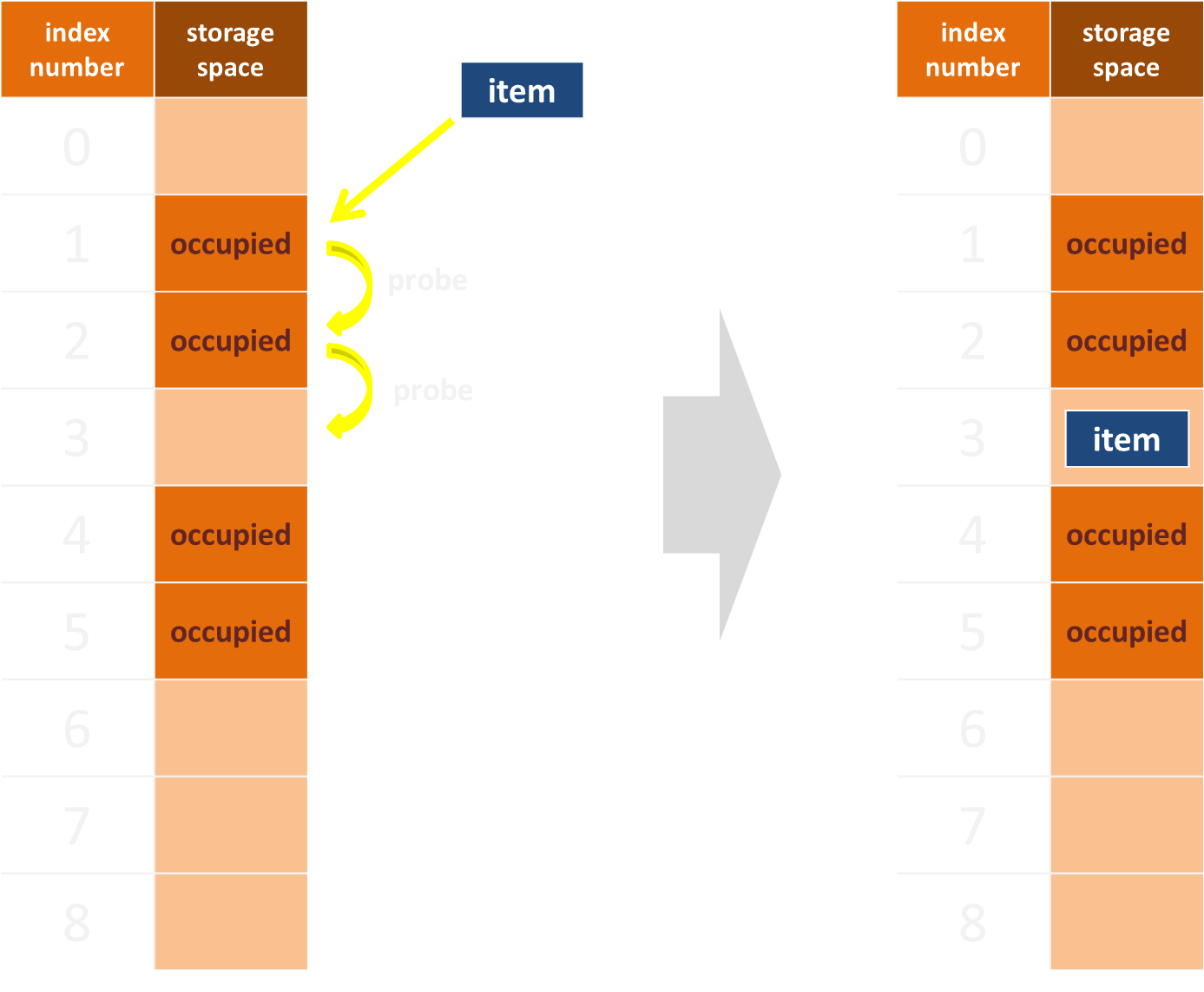
使用「線性探測法(linear probing)」實現開放尋址
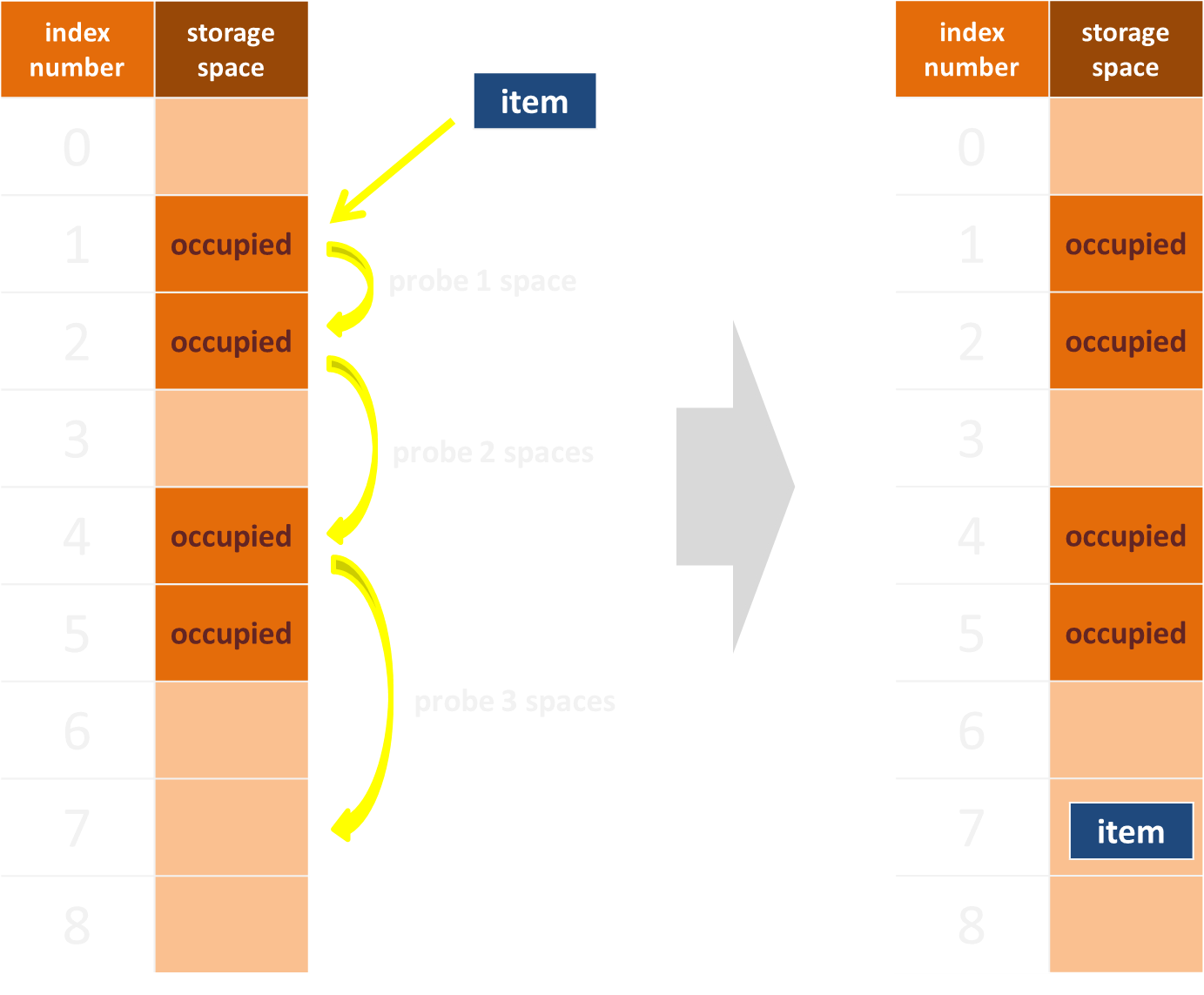
使用「平方探測法(quadratic probing)」實現開放尋址
若不使用探測,也可在衝突發生時,再跑另一個雜湊函式,也就是「雙雜湊(double hashing)」,若依然衝突,則持續進行雜湊運算,直到沒有衝突為止。現假設第一個雜湊函式為 F₁(x)、第二個雜湊函式為 F₂(x),而要計算的「key」值為 k:
- 第一次雜湊函式運算,得 index₁=F₁(k)。
- 若有衝突,進行第二次雜湊運算,得 index₂=F₁(k)+1*F₂(k)。
- 若仍有衝突,進行第三次雜湊運算,得 index₃=F₁(k)+2*F₂(k)。
- 若仍有衝突,進行第三次雜湊運算,得 index₄=F₁(k)+3*F₂(k)。
若仍有衝突則按「indexₙ=F₁(k)+(n–1)*F₂(k)」的規則持續運算,直到找到的「indexₙ」不再與舊的儲存資料有衝突為止。
程式碼範例(JavaScript)
下列程式碼以「陣列」實現封閉循址處理雜湊衝突。
class HashTable {
constructor(size){
this.size = size;
this.table = [];
//要在table這個陣列中每個索引值對應的位置都再放入小陣列
for(let i=0; i<this.size; i++){
this.table.push([]);
}
}
//以除法實現雜湊函式
hash1(key){
return key%(this.size);
}
//以乘法實現雜湊函式
hash2(key){
let A = (Math.sqrt(5)-1)/2;
return Math.floor((this.size)*((key*A)%1));
}
//將一筆key-value pair放進雜湊表
set(key, value){
let index = this.hash2(key); //用雜湊函式處理key值,設定該筆資料索引值
this.table[index].push({key,value}); //以物件形式將key-value pair放進對應索引位置
}
//輸入key值,從雜湊表取得對應的value
get(key){
let index = this.hash2(key); //用雜湊函式處理key值,找到該筆資料索引值
//因可能有雜湊衝突,即同一個索引位置有不只一筆資料,因此用for迴圈在該索引位置內跑,找到與輸入key值相符者才是正確資料
for(let i = 0; i < this.table[index].length; i++){
if(this.table[index][i].key === key){
console.log(this.table[index][i]);
return;
}
}
console.log("not in this table") //如果雜湊表中找不到對應資料,則顯示"not in this table"
}
//顯示雜湊表
printAll(){
console.log(this.table);
}
}
時間複雜度
- 平均&最佳情況:O(1),在多數情況下,可透過雜湊函式求「key」值,直接找到對應位置並進行操作。
- 最差情況:O(n),若產生雜湊衝突且使用「封閉循址法」處理,則在同一個「key」值的儲存空間中要再做一次搜尋。
空間複雜度
視處理雜湊衝突時使用「封閉尋址法」或「開放定址法」而定:
- 封閉循址法:O(m+n) = O(n),原本雜湊表的大小為 m,但另外需要 n 個儲存空間處理對應到同一索引值的資料。
- 開放定址法:O(n),資料透過不斷探測,在原雜湊表中找到空的位置儲存,所有資料佔據的總空間大小不變。
_1661. Average Time of Process per Machine_@ikl258794613_https://static.coderbridge.com/images/covers/default-post-cover-1.jpg)

_Redux basic_@Jing-Teng_https://static.coderbridge.com/images/covers/default-post-cover-2.jpg)

_Day 17-OOP & Quiz Game_@zxc61224_https://static.coderbridge.com/images/covers/default-post-cover-3.jpg)
